Next.js에서 성능 최적화 해보기
문제를 발견한 계기
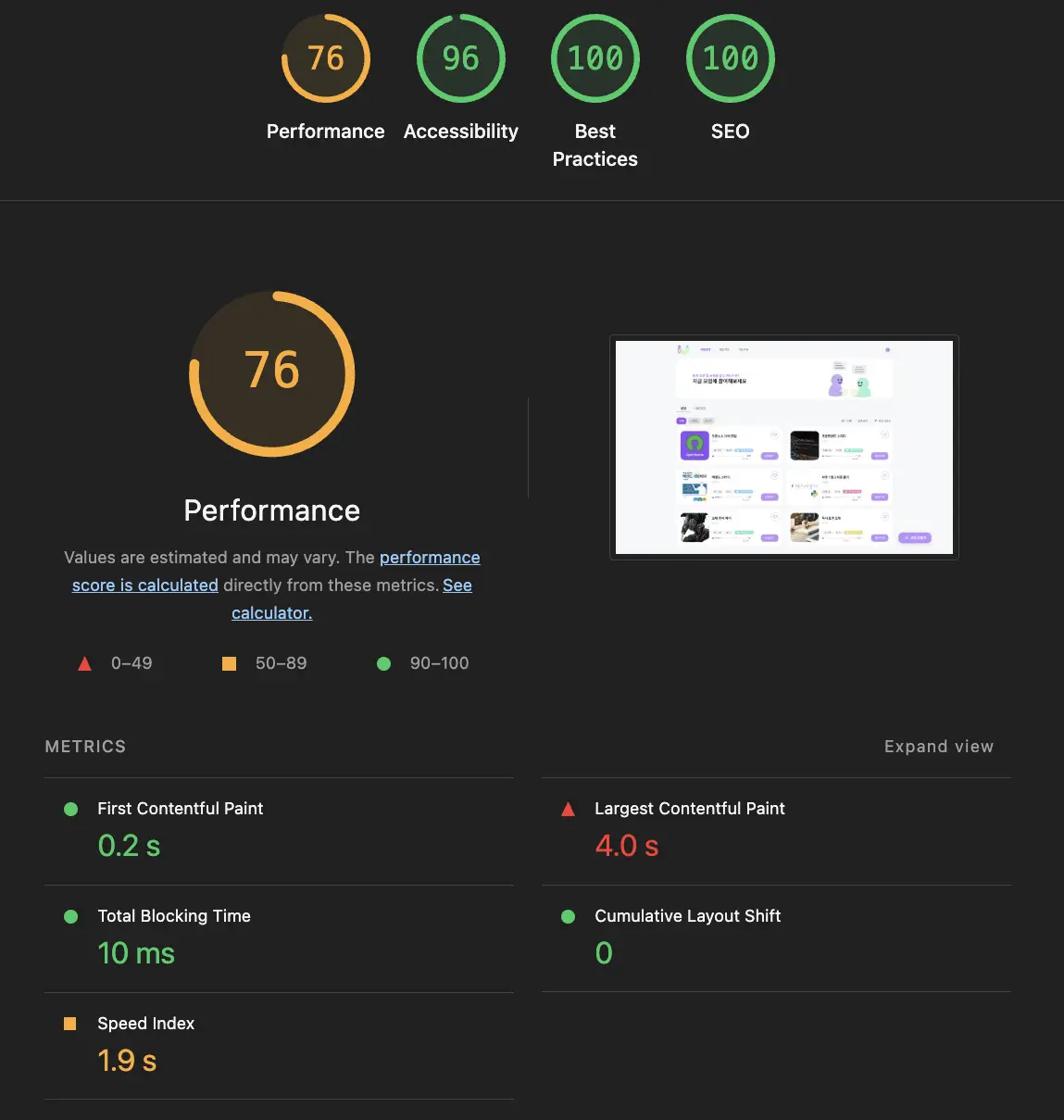
UPDO는 모임을 만들고 참여할 수 있는 커뮤니티 서비스다. 기능 구현이 어느 정도 마무리된 시점에 처음으로 Lighthouse를 돌려봤다.
Performance 점수가 76이었고 LCP가 4초가 나왔다. 페이지에 접속해서 콘텐츠가 보이기까지 4초나 걸린다는 뜻이다. 체감상 느리다고 느끼긴 했는데 수치로 보니까 생각보다 심각했다. 모임 목록을 볼 수 있는 페이지가 서비스의 메인인데 여기서부터 느리면 사용자 경험이 좋지 않을 것 같아서 개선을 시작했다.
뭐가 느린지 알아보기
Lighthouse 점수만 보고는 어디가 문제인지 감이 안 잡혔다. 그래서 DevTools의 Network 탭을 열고 모임 찾기 페이지를 로드해봤다.

눈에 들어온 게 크게 세 가지였다.
첫 번째는 빈 HTML이었다. 서버에서 내려오는 HTML을 열어보니 모임 목록 데이터가 아예 없었다. 껍데기만 있는 HTML이 도착하고 브라우저가 JavaScript를 다운로드하고 실행한 다음에야 비로소 API 호출이 시작되는 구조였다. HTML 도착 → JS 다운로드 → JS 실행 → API 호출 → 응답 → 렌더링이 전부 직렬로 이어지고 있었다. 사용자 입장에서는 페이지에 접속한 뒤 한참 동안 빈 화면이나 스켈레톤만 보게 되는 셈이다.
왜 이렇게 됐는지 보니 모임 찾기 페이지가 사실상 CSR(Client-Side Rendering) 구조였다. 페이지 컴포넌트 자체는 서버 컴포넌트였지만 데이터를 가져오는 로직은 전부 클라이언트 컴포넌트 안에 있었다. 서버는 레이아웃과 빈 컨테이너만 렌더링하고 실제 콘텐츠는 클라이언트에서 채우고 있었던 것이다.
두 번째는 폰트 파일 크기였다. Pretendard 폰트를 next/font/local로 직접 호스팅하고 있었는데 한국어 폰트라서 파일 하나가 약 780KB나 됐다. 이걸 5개 weight(Light, Regular, Medium, SemiBold, Bold)로 불러오고 있었으니 폰트만 약 3.9MB를 다운로드하고 있었다. 폰트 파일이 렌더링 블로킹 리소스로 잡혀서 다운로드가 끝날 때까지 텍스트가 화면에 표시되지 않고 있었다.
세 번째는 번들 크기였다. framer-motion 라이브러리가 전체 모듈을 포함한 채로 번들에 들어가 있었다. @next/bundle-analyzer로 트리맵을 확인해보니 framer-motion이 proxy.mjs 포함 245개 모듈을 끌고 오고 있었다. 실제로 쓰는 건 간단한 DOM 애니메이션뿐인데 필요 없는 코드까지 전부 같이 내려가고 있었다.
데이터 페칭을 서버로 옮기기
세 가지 문제 중에서 먼저 손댈 곳은 데이터 페칭 타이밍이라고 판단했다. 폰트와 번들은 로딩 속도에 영향을 주지만 데이터가 아예 없는 HTML을 내려보내는 건 LCP 자체를 구조적으로 늦추는 문제이기 때문이다.
CSR과 SSR의 차이점
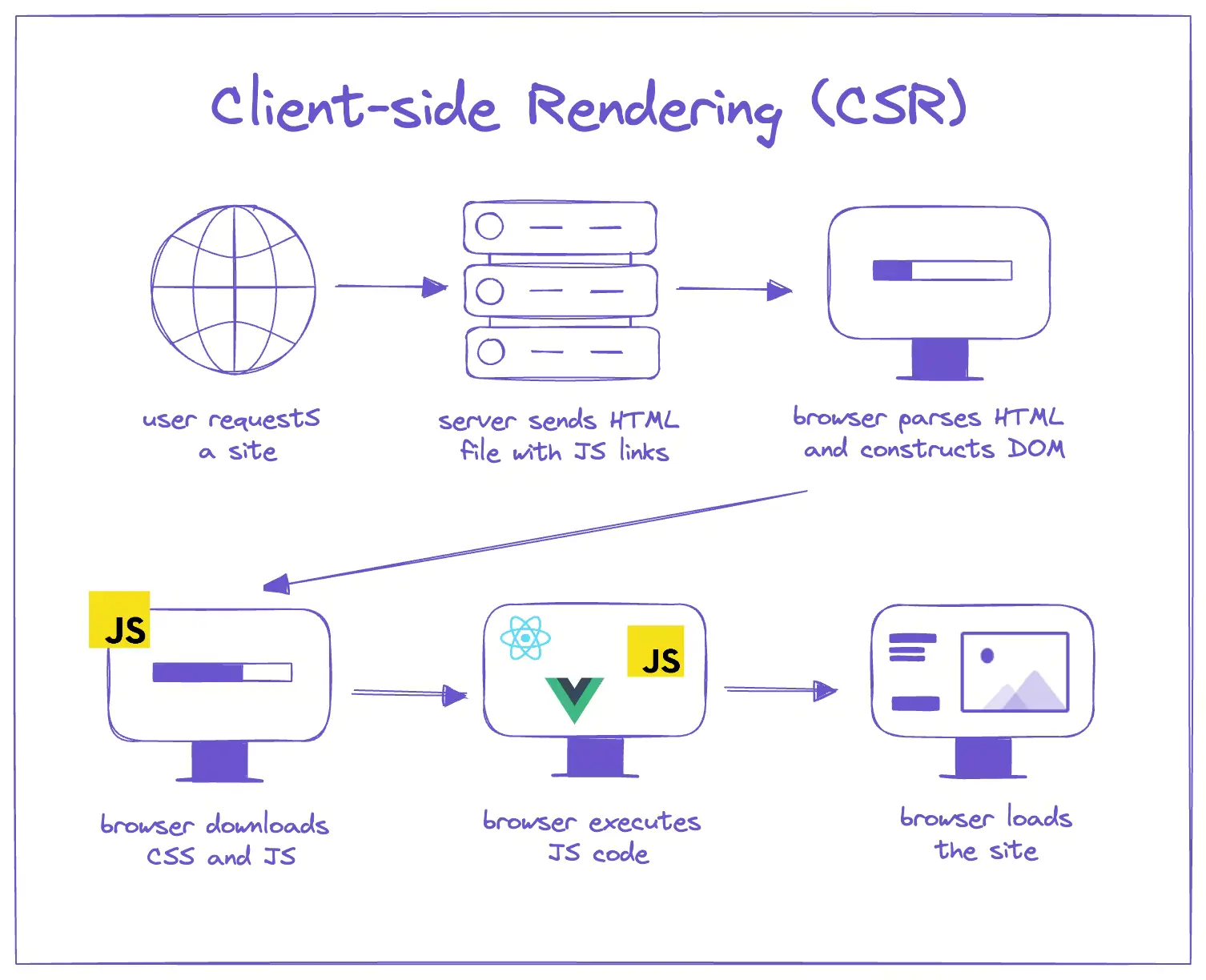
일반적인 React 앱은 CSR(Client-Side Rendering) 방식으로 동작한다. 서버는 거의 비어 있는 HTML과 JavaScript 번들만 보내고 브라우저가 JS를 실행해서 화면을 그린다. 사용자는 JS가 다운로드되고 실행될 때까지 빈 화면을 보게 된다.
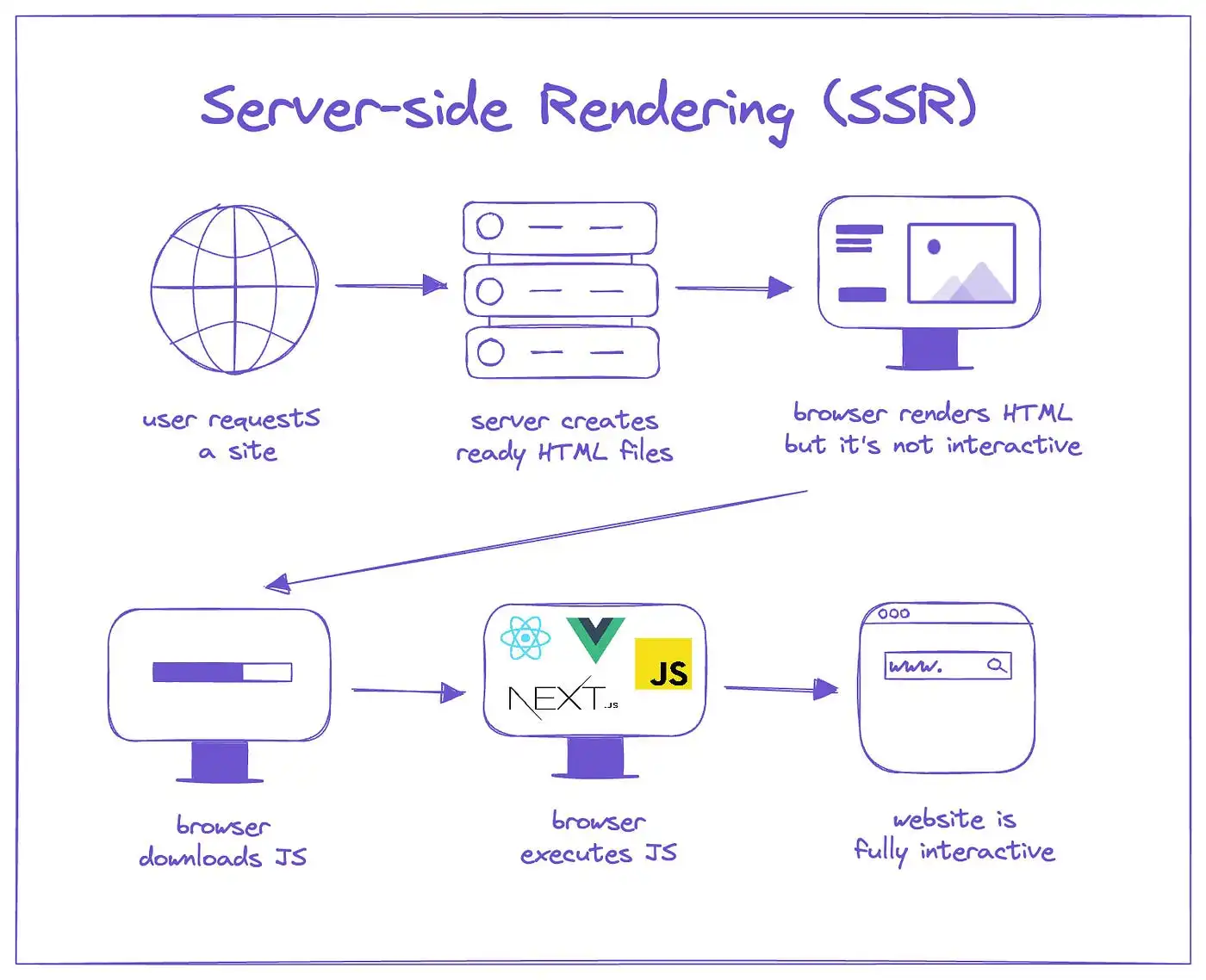
SSR(Server-Side Rendering) 은 서버에서 React 컴포넌트를 미리 렌더링해서 완성된 HTML을 보내는 방식이다. 브라우저는 HTML을 받자마자 콘텐츠를 표시할 수 있고 JS가 로드되면 이벤트 핸들러 같은 인터랙션이 붙는다. Next.js의 App Router에서는 서버 컴포넌트가 기본이라 별도 설정 없이 SSR이 적용된다.
그런데 SSR을 쓴다고 해서 자동으로 데이터까지 채워지는 건 아니다. 서버 컴포넌트에서 데이터를 가져오는 코드가 없으면 HTML에는 레이아웃만 들어가고 실제 콘텐츠는 여전히 클라이언트에서 채워야 한다. 이 프로젝트가 딱 그 상태였다. 여기서 필요한 게 SSR prefetch다.
SSR prefetch
SSR prefetch는 서버에서 페이지를 렌더링하기 전에 필요한 데이터를 미리 불러와서 HTML에 포함시키는 것이다. 이 프로젝트에서는 데이터 페칭에 TanStack Query를 쓰고 있었는데 TanStack Query가 SSR prefetch를 위한 API(prefetchQuery, dehydrate, HydrationBoundary)를 제공하고 있어서 이걸 활용했다.
일반적인 CSR 흐름을 보면 이렇다.
- 브라우저가 서버에 페이지 요청
- 서버가 빈 HTML(레이아웃 + JS 번들 참조) 응답
- 브라우저가 JS 번들 다운로드 및 실행
- React가 마운트되면서
useQuery등으로 API 호출 - API 응답을 받아서 화면 렌더링
SSR prefetch를 적용하면 이렇게 바뀐다.
- 브라우저가 서버에 페이지 요청
- 서버가 API를 먼저 호출해서 데이터를 가져옴
- 데이터가 포함된 HTML 응답
- 브라우저가 JS 번들 다운로드 및 실행
- React가 마운트되면서 이미 있는 데이터로 바로 렌더링 (추가 API 호출 없음)
핵심 차이는 3단계에 있다. CSR에서는 빈 HTML이 오고 클라이언트에서 데이터를 가져올 때까지 기다려야 하지만 SSR prefetch에서는 서버가 데이터를 채워서 보내기 때문에 HTML이 도착하는 순간 콘텐츠가 이미 들어있다. 사용자는 JavaScript가 실행되기 전에도 콘텐츠를 볼 수 있고 LCP도 그만큼 앞당겨진다.
TanStack Query에서 prefetch가 동작하는 원리
TanStack Query에서는 이 SSR prefetch를 세 단계로 처리한다. 각 단계에서 쓰이는 개념들이 처음에는 낯설 수 있어서 하나씩 풀어보려 한다.
1단계: 서버에서 QueryClient를 만들고 캐시를 채운다.
서버 컴포넌트에서 new QueryClient()로 새 인스턴스를 만들고 prefetchQuery 또는 prefetchInfiniteQuery를 호출한다. 이 함수는 queryFn에 지정한 API 호출을 실행하고 응답을 QueryClient의 내부 캐시에 저장한다. 여기까지는 단순하다. 서버에서 API를 먼저 불러서 캐시에 넣어둔 것뿐이다.
2단계: dehydrate — 캐시를 직렬화한다.
문제는 서버의 QueryClient 인스턴스를 브라우저로 그대로 보낼 수 없다는 점이다. QueryClient는 메모리에 존재하는 JavaScript 객체라서 HTTP 응답으로 전달하려면 JSON 같은 텍스트 형태로 변환해야 한다. dehydrate(queryClient)가 하는 일이 바로 이것이다. QueryClient의 캐시 상태를 일반 JavaScript 객체로 변환해서 HTML에 담아 보낼 수 있게 만든다.
이름이 "dehydrate(탈수)"인 이유는 동작하는 QueryClient 인스턴스에서 수분(메서드, 이벤트 리스너 같은 런타임 기능)을 빼고 순수 데이터만 남긴다는 비유에서 왔다.
3단계: HydrationBoundary — 클라이언트에서 캐시를 복원한다.
HydrationBoundary는 2단계에서 건조시킨 데이터를 받아서 클라이언트의 QueryClient 캐시에 다시 주입하는 컴포넌트다. "hydration(수분 보충)"이라는 이름 그대로 건조했던 데이터에 다시 수분을 채워서 동작하는 캐시로 되살리는 과정이다.
이 과정이 끝나면 클라이언트의 useInfiniteQuery가 실행될 때 캐시에 이미 데이터가 있으니 API를 다시 호출하지 않고 바로 그 데이터를 가져다 렌더링한다. 사용자 입장에서는 페이지가 열리자마자 콘텐츠가 보이는 것이다.
정리하면 서버에서 캐시 채우기 → dehydrate로 직렬화 → HydrationBoundary로 클라이언트에 전달이라는 세 단계를 거쳐서 서버와 클라이언트 간에 데이터를 끊김 없이 이어주는 구조다.
기존 코드: prefetch 없는 구조
import GatheringSection from '@/components/feature/gathering/GatheringSection';
import Image from 'next/image';
export default function GatheringPage() {
return (
<>
<header className="flex h-[192px] w-full items-center justify-between rounded-3xl bg-white sm:h-[244px]">
<div className="ml-5 flex flex-col justify-center text-nowrap sm:ml-24">
<p className="typo-body-sm sm:typo-subtitle text-[var(--purple-550)]">
함께 성장 할 사람을 찾고 계신가요?
</p>
<p className="card-title sm:h3Semibold">지금 모임에 참여해보세요</p>
</div>
<div className="flex h-44 w-36 items-center justify-center sm:mr-16 sm:h-auto sm:w-[275px] md:mr-24 md:w-[316px]">
<Image
src="/images/find_banner.png"
alt="모임 찾기 배너"
width={310}
height={70}
priority
style={{ width: 'auto', height: 'auto' }}
/>
</div>
</header>
<main>
<GatheringSection />
</main>
</>
);
}GatheringPage 자체는 서버 컴포넌트인데 실제 데이터를 가져오는 건 GatheringSection 내부의 클라이언트 컴포넌트다. 서버는 배너 이미지와 텍스트만 렌더링하고 모임 목록은 비워둔 채로 HTML을 보낸다. GatheringSection이 브라우저에서 마운트된 뒤에야 useInfiniteQuery가 API를 호출하기 시작하는 구조였다.
개선된 코드: SSR prefetch 적용
import { dehydrate, HydrationBoundary, QueryClient } from '@tanstack/react-query';
import { Suspense } from 'react';
import GatheringSection from '@/components/feature/gathering/GatheringSection';
import GatheringSkeleton from '@/components/ui/Skeleton/GatheringSkeleton';
import { queryKeys } from '@/constants/queryKeys';
import { getGatheringInfiniteList } from '@/services/gatherings/anonGatheringService';
import { normalizeFilters } from '@/utils/filters';
import { toGetGatheringsParams } from '@/utils/mapping';
export const dynamic = 'force-dynamic';
export default async function GatheringPage() {
const queryClient = new QueryClient();
const defaultFilters = normalizeFilters({ main: '성장', subType: '전체' });
await queryClient.prefetchInfiniteQuery({
queryKey: queryKeys.gatherings.infiniteList(defaultFilters),
queryFn: ({ pageParam = 1 }) =>
getGatheringInfiniteList(pageParam, toGetGatheringsParams(defaultFilters)),
initialPageParam: 1,
});
return (
<HydrationBoundary state={dehydrate(queryClient)}>
<Suspense fallback={<GatheringSkeleton />}>
<GatheringSection defaultFilters={defaultFilters} />
</Suspense>
</HydrationBoundary>
);
}바뀐 부분을 하나씩 보면
함수 선언에 async 가 붙었다. 서버 컴포넌트이기 때문에 async를 쓸 수 있고 렌더링 전에 await로 데이터를 기다릴 수 있다.
prefetchInfiniteQuery가 서버에서 모임 목록 API를 호출하고 응답을 QueryClient 캐시에 저장한다. queryKey에 필터 조건을 넣어서 클라이언트의 useInfiniteQuery가 같은 키로 캐시를 찾을 수 있게 했다.
dehydrate(queryClient)가 캐시를 직렬화하고 HydrationBoundary가 이걸 자식 컴포넌트들에게 전달한다. GatheringSection 안의 useInfiniteQuery가 마운트될 때 캐시에서 데이터를 찾아서 추가 API 호출 없이 바로 렌더링하게 된다.
Suspense는 API 응답이 느릴 경우를 대비한 안전장치다. await로 데이터를 기다리고 있어서 대부분의 경우 fallback이 보이지 않지만 혹시 API가 느려지면 GatheringSkeleton을 보여줘서 빈 화면이 뜨는 걸 방지한다.
QueryProvider: 서버와 클라이언트의 QueryClient 분리
서버에서 만든 캐시를 클라이언트에서 받으려면 QueryClient의 생성 방식을 서버와 클라이언트에서 다르게 가져가야 한다.
'use client';
import {
isServer,
QueryClient,
QueryClientProvider,
} from '@tanstack/react-query';
function makeQueryClient() {
return new QueryClient({
defaultOptions: {
queries: {
staleTime: 1000 * 60 * 3,
gcTime: 1000 * 60 * 10,
refetchOnWindowFocus: false,
},
},
});
}
let browserQueryClient: QueryClient | undefined = undefined;
function getQueryClient() {
if (isServer) {
return makeQueryClient();
} else {
if (!browserQueryClient) browserQueryClient = makeQueryClient();
return browserQueryClient;
}
}서버에서는 요청마다 새 QueryClient를 만든다. 서버는 여러 사용자의 요청을 동시에 처리하는데 만약 하나의 QueryClient를 공유하면 A 사용자의 캐시 데이터가 B 사용자의 응답에 섞일 수 있다. 그래서 요청마다 독립된 인스턴스를 만들어야 한다.
브라우저에서는 한 번 만든 QueryClient를 계속 쓴다. 브라우저는 한 명의 사용자만 쓰니까 싱글턴으로 충분하다. 서버에서 dehydrate로 직렬화한 캐시가 이 QueryClient에 주입되고 이후 클라이언트에서 발생하는 모든 쿼리가 같은 캐시를 참조한다.
이 분기 처리에 TanStack Query의 isServer 유틸을 사용했다. isServer는 현재 코드가 서버에서 실행 중인지 클라이언트에서 실행 중인지를 알려주는 boolean 값이다. 이걸로 간단하게 서버와 클라이언트의 QueryClient 생성 로직을 분리할 수 있다.
staleTime
prefetch를 적용했는데 Network 탭을 보니 클라이언트에서 똑같은 API 요청이 또 나가고 있었다. 서버에서 데이터를 미리 가져왔는데 클라이언트가 그걸 무시하고 다시 호출하고 있었다.
원인은 staleTime이었다. TanStack Query의 기본 staleTime은 0이다. 이건 캐시에 데이터가 있어도 즉시 stale(낡은 상태)로 판단한다는 뜻이다. 서버에서 캐시를 채워서 보냈지만 클라이언트에서 useInfiniteQuery가 마운트되는 순간 "이 캐시는 낡았으니 다시 가져와야 해"라고 판단해서 API를 재호출하고 있었던 것이다.
staleTime을 3분(1000 * 60 * 3)으로 설정하니까 해결됐다. 서버에서 채운 캐시가 3분 동안 fresh 상태로 유지되면서 컴포넌트가 마운트될 때 재요청이 발생하지 않는다. 3분이 지나서 캐시가 stale 상태가 되면 다음에 컴포넌트가 마운트될 때 자동으로 최신 데이터를 가져온다.
처음에는 refetchOnMount: false도 같이 설정했었는데 이러면 staleTime이 지난 뒤에도 재요청을 막아버려서 사용자가 낡은 데이터를 계속 보게 되는 문제가 있었다. force-dynamic으로 서버에서는 항상 최신 데이터를 보장하면서 클라이언트에서는 갱신을 막아버리는 건 모순이라고 봤다. staleTime만 적절히 설정하면 SSR prefetch 직후 중복 요청도 방지되고 일정 시간 뒤에는 자연스럽게 갱신도 되니까 이쪽이 더 맞다고 판단했다.
force-dynamic
코드에 export const dynamic = 'force-dynamic'이 선언돼 있다. 이건 Next.js에게 "이 페이지를 빌드 타임에 정적으로 생성하지 말고 매 요청마다 서버에서 새로 렌더링하라"고 지시하는 것이다.
이걸 쓰면 빌드 타임 캐싱(SSG)이나 ISR(Incremental Static Regeneration)의 이점을 포기하게 된다. 매 요청마다 서버에서 API를 호출하고 HTML을 새로 만드니까 서버 부하가 늘어나는 단점이 있다.
그런데 모임 데이터는 실시간으로 바뀐다. 참여자 수가 늘거나 모임이 마감되거나 새 모임이 생기는 게 수시로 일어난다. ISR로 60초마다 재검증하는 방식을 쓰면 그 사이에 낡은 데이터를 보여줄 수 있는데 모임 참여 가능 여부가 틀리게 표시되면 사용자한테 혼란을 줄 수 있다고 생각했다.
force-dynamic을 쓰면 매 요청마다 최신 데이터를 보장하면서도 SSR prefetch 덕분에 HTML에 데이터가 포함돼서 LCP는 빠르게 유지할 수 있다. 정적 캐싱은 포기하지만 사용자에게 항상 최신 데이터를 보여주는 쪽을 선택한 것이다.
적용 전후 비교
실제로 서버에서 내려오는 HTML을 열어보면 차이가 확연하다.
적용 전에는 모임 목록이 들어갈 자리가 빈 div로만 내려오고 있었다. 데이터가 없으니 브라우저가 JS를 실행하고 API를 호출할 때까지 그 자리는 비어 있는 상태다.
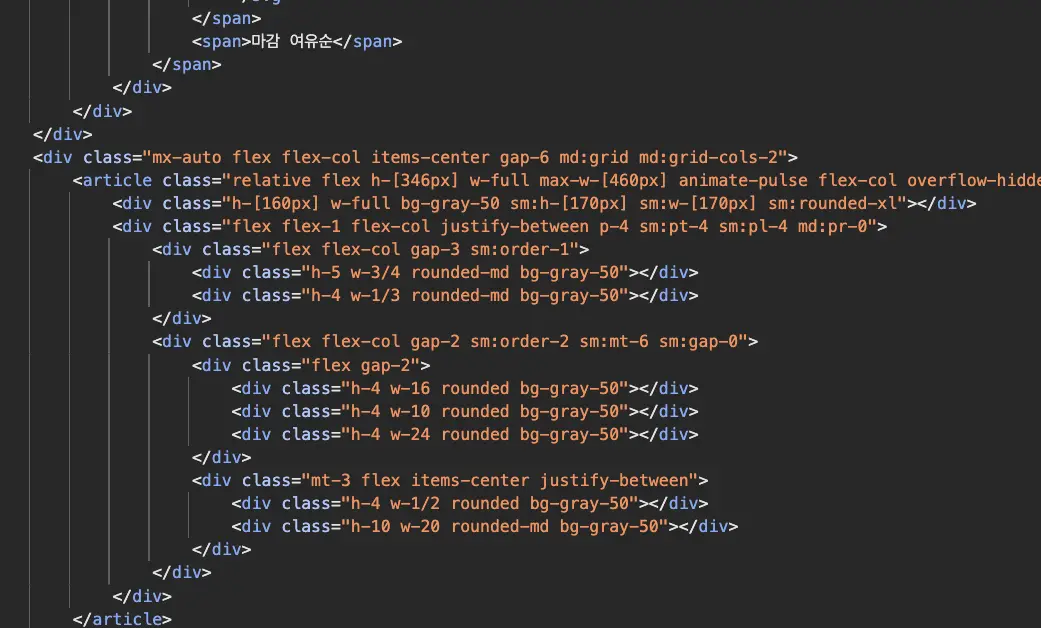
적용 후에는 같은 자리에 모임 카드 데이터가 이미 채워진 채로 HTML이 내려온다. 브라우저가 HTML을 받는 순간 바로 콘텐츠를 표시할 수 있다. SEO 측면에서도 의미가 있는데 기존 CSR 구조에서는 검색 엔진 크롤러가 빈 div만 보고 돌아갔을 것이다. HTML에 데이터가 채워지면서 크롤러가 모임 목록 콘텐츠를 직접 읽을 수 있게 됐다.
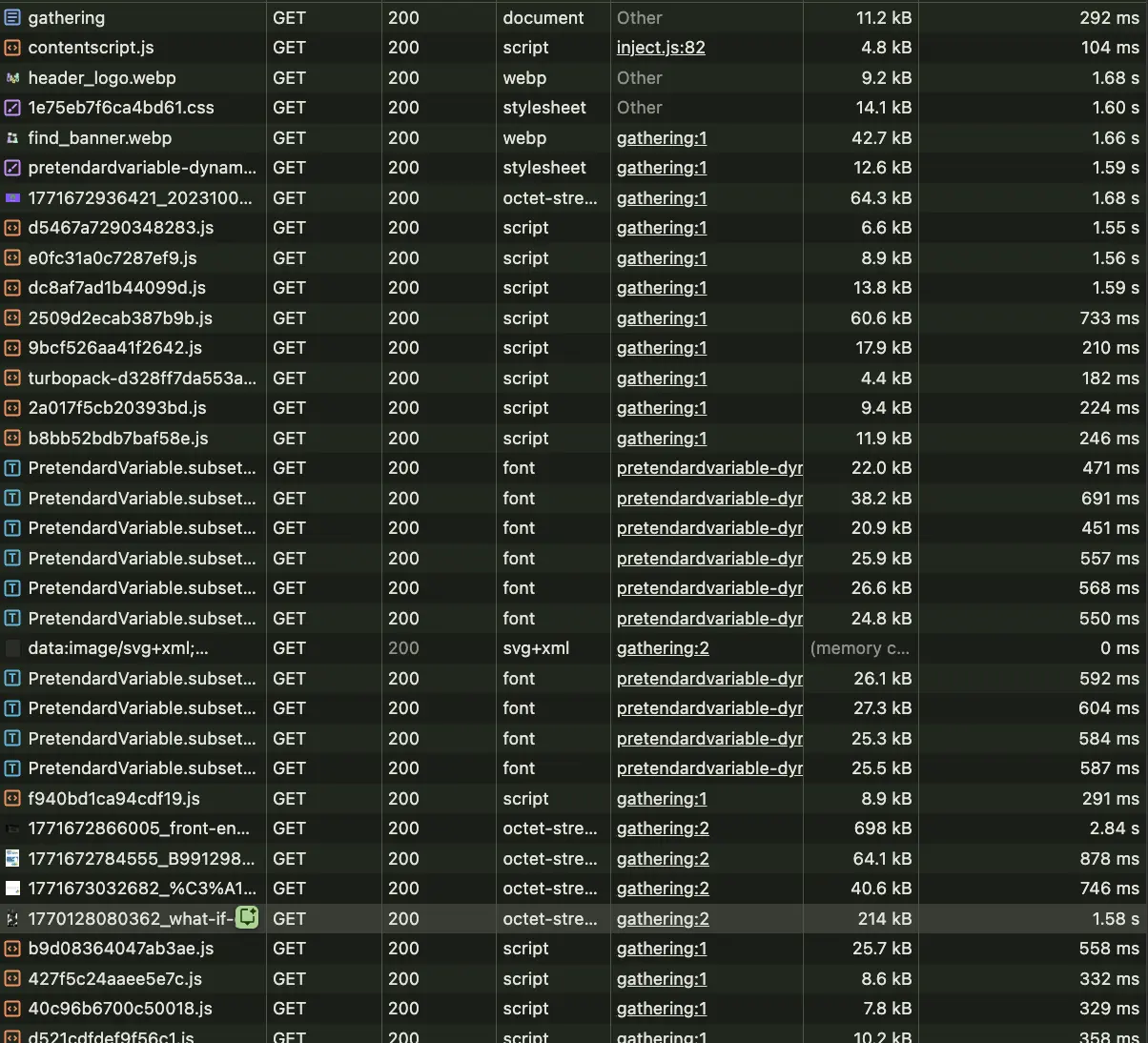
Network 탭에서도 변화가 보인다. 기존에는 JS가 실행된 뒤에야 모임 목록 API 호출이 나갔는데 적용 후에는 document 응답 자체에 데이터가 포함돼 있어서 클라이언트에서 별도의 API 호출이 발생하지 않는다.
폰트 로딩 방식 바꾸기
기존 방식: next/font/local
개선 전에는 next/font/local로 Pretendard를 직접 호스팅해서 쓰고 있었다.
import localFont from 'next/font/local';
export const Pretendard = localFont({
src: [
{ path: '../../public/fonts/Pretendard-Light.woff2', weight: '300' },
{ path: '../../public/fonts/Pretendard-Regular.woff2', weight: '400' },
{ path: '../../public/fonts/Pretendard-Medium.woff2', weight: '500' },
{ path: '../../public/fonts/Pretendard-SemiBold.woff2', weight: '600' },
{ path: '../../public/fonts/Pretendard-Bold.woff2', weight: '700' },
],
variable: '--font-pretendard',
display: 'swap',
});그리고 레이아웃에서 이렇게 적용하고 있었다.
import { Pretendard } from '../lib/font';
export default function RootLayout({
children,
}: {
children: React.ReactNode;
}) {
return (
<html lang="ko" className={Pretendard.variable}>
<body>...</body>
</html>
);
}앞서 언급했듯이 한국어 폰트는 글리프 수가 많아서 파일 하나가 약 780KB이고 5개 weight를 합하면 약 3.9MB에 달했다. 페이지에서 실제로 쓰는 글자가 몇십 자밖에 안 되더라도 전체 폰트 파일을 내려받아야 했다.
display: 'swap'을 설정했으니 텍스트 자체는 시스템 폰트로 먼저 보이긴 하지만 폰트 다운로드가 완료되면 텍스트가 깜빡이면서 폰트가 교체된다. 3.9MB를 다 받을 때까지 이 깜빡임이 계속되니까 사용자 경험에도 좋지 않았다. 폰트 파일 크기 자체를 줄여야 했다.
dynamic-subset이 뭔지
Pretendard는 dynamic-subset 버전을 제공한다. 이건 폰트 파일을 유니코드 범위(Unicode Range)별로 잘게 쪼개놓은 방식이다.
일반 폰트 파일은 한글 글리프 수천 개를 하나의 파일에 전부 담고 있다. dynamic-subset은 이걸 작은 조각들로 쪼갠다. 한글을 가나다순으로 나눠서 "가"로 시작하는 글자들은 파일 하나, "까"로 시작하는 글자들은 또 다른 파일에 넣는 식이다. 그리고 CSS @font-face의 unicode-range 속성으로 각 파일이 어떤 글자 범위를 담당하는지 지정해둔다.
브라우저는 페이지에서 실제로 사용하는 글자들을 확인한 뒤 해당 글자가 속한 범위의 폰트 파일만 요청한다. "모임 찾기"라는 텍스트가 있으면 "모", "임", "찾", "기"가 속한 범위의 서브셋 파일만 다운로드하고 나머지는 아예 요청하지 않는다.
결과적으로 전체 780KB짜리를 통째로 받는 대신 실제 사용하는 글자 범위의 파일들만 20~30KB씩 내려받게 된다. 페이지에 따라 다르지만 대부분의 경우 총 다운로드 크기가 기존의 1/10 이하로 줄어든다.
CDN으로 전환한 코드
next/font/local을 걷어내고 Pretendard CDN의 dynamic-subset variable 버전으로 교체했다.
<head>
<link
rel="preconnect"
href="https://cdn.jsdelivr.net"
crossOrigin="anonymous"
/>
<link
rel="preload"
as="style"
href="https://cdn.jsdelivr.net/gh/orioncactus/pretendard@v1.3.9/dist/web/variable/pretendardvariable-dynamic-subset.min.css"
crossOrigin="anonymous"
/>
<link
rel="stylesheet"
crossOrigin="anonymous"
href="https://cdn.jsdelivr.net/gh/orioncactus/pretendard@v1.3.9/dist/web/variable/pretendardvariable-dynamic-subset.min.css"
/>
</head>variable 폰트를 쓰면 weight별로 별도 파일을 로드할 필요가 없다. 하나의 variable 폰트 파일이 300~700 weight를 전부 커버한다. 여기에 dynamic-subset까지 적용되니까 weight 5개 x 780KB의 문제가 한 번에 해결됐다.
preconnect와 preload
preconnect 는 브라우저에게 "이 CDN 서버에 곧 뭔가 요청할 거니까 미리 연결해둬"라고 알려주는 것이다. 웹에서 서버에 처음 요청을 보내려면 DNS 조회, TCP 연결, TLS(보안) 협상이라는 준비 과정이 필요한데 이게 보통 100~300ms 정도 걸린다. preconnect를 쓰면 이 준비를 미리 해둬서 나중에 실제로 폰트 파일을 요청할 때 바로 다운로드를 시작할 수 있다.
preload as="style" 은 브라우저에게 "이 CSS 파일이 곧 필요하니까 지금 바로 다운로드해"라고 지시하는 것이다. 보통 브라우저는 HTML을 위에서 아래로 읽으면서 리소스를 발견할 때마다 요청을 보내는데 preload를 쓰면 HTML을 다 읽기 전에 먼저 요청을 시작할 수 있다.
이 두 가지를 같이 쓰면 CDN 연결과 CSS 다운로드가 다른 작업(HTML 파싱, JS 다운로드 등)과 동시에 진행된다. 선언 순서도 중요한데 preconnect → preload → stylesheet 순서로 써야 한다. 연결을 먼저 맺고 그 연결을 통해 파일을 미리 받아두고 마지막에 스타일을 적용하는 흐름이다.

최적화 전
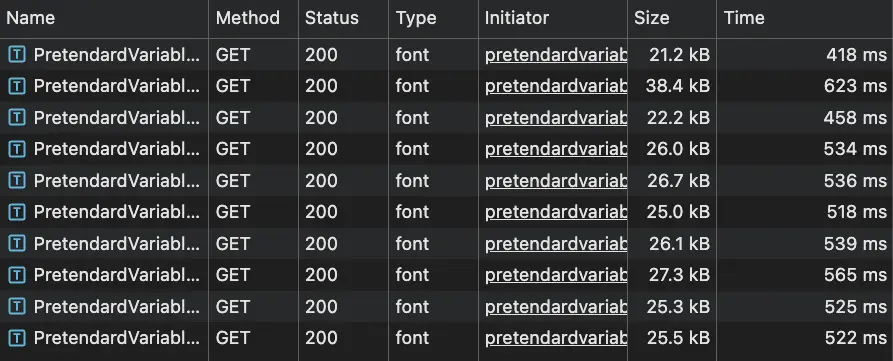
최적화 후
번들과 이미지 최적화
framer-motion 부분 임포트
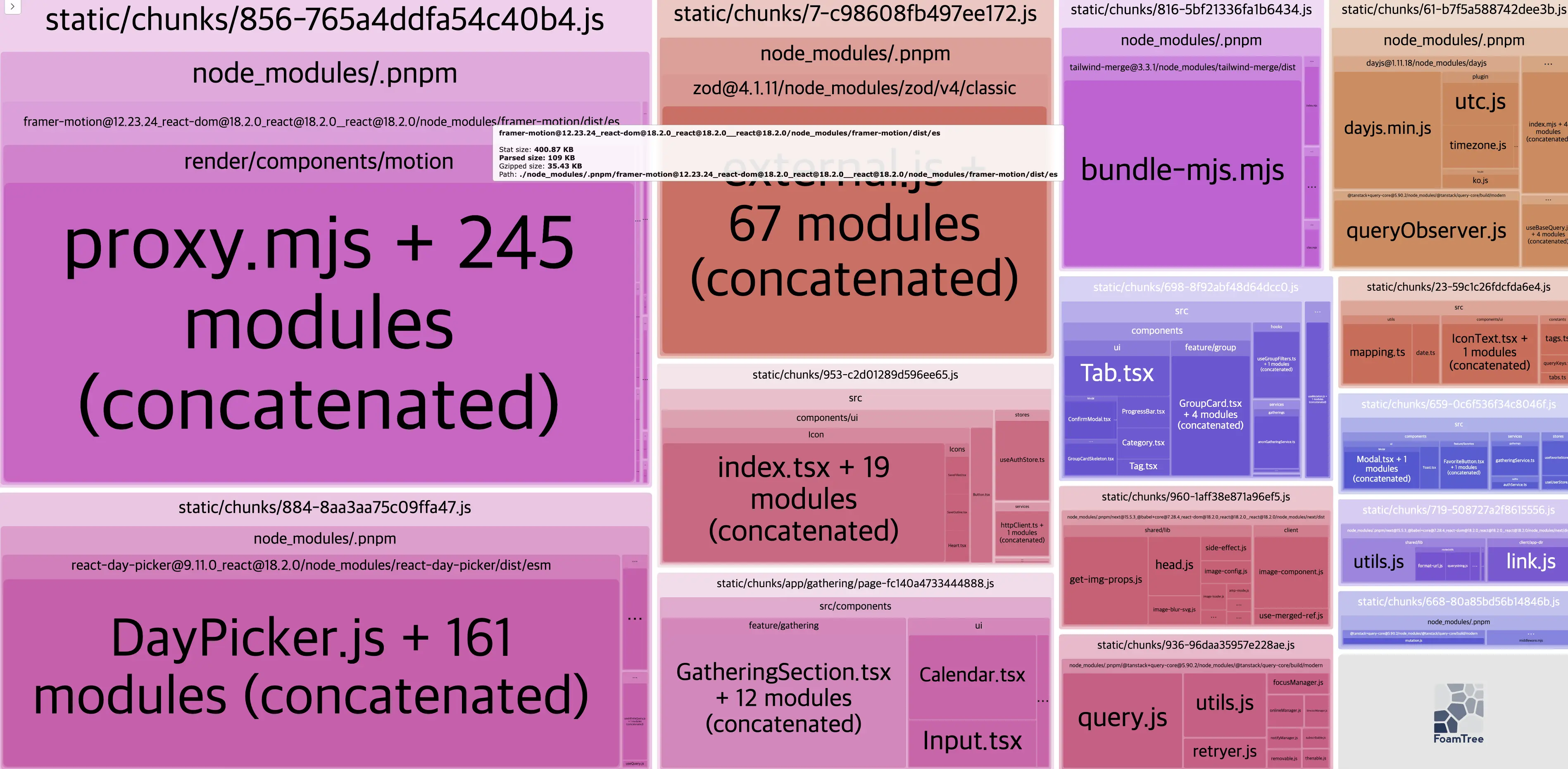
@next/bundle-analyzer로 트리맵을 열어보니 문제가 되는 라이브러리가 두 개 보였다. 앞서 확인한 framer-motion과 함께 react-day-picker도 날짜 선택 컴포넌트 하나 때문에 전체 라이브러리가 통째로 들어와 있었다. framer-motion은 기본 import { motion } from 'framer-motion'으로 쓰면 레이아웃 애니메이션, SVG 애니메이션, 3D 변환 등 전체 기능이 번들에 포함되는데 실제로 쓰는 건 간단한 DOM 애니메이션뿐이었다.
개선 전 레이아웃 코드에는 LazyMotion이 없었다.
// before: layout.tsx
<QueryProvider>
<AuthProvider>
<AuthSessionWatcher />
<ScrollWrapper />
<Header />
<Toast />
<main className="layout-container font-sans">{children}</main>
</AuthProvider>
</QueryProvider>framer-motion의 LazyMotion 컴포넌트에 domAnimation feature set만 전달하면 DOM 기반 애니메이션에 필요한 최소 코드만 로드할 수 있다.
// after: layout.tsx
import { domAnimation, LazyMotion } from 'framer-motion';
<QueryProvider>
<AuthProvider>
<LazyMotion features={domAnimation}>
<AuthSessionWatcher />
<ScrollWrapper />
<Header />
<Toast />
<main className="layout-container font-sans">{children}</main>
</LazyMotion>
</AuthProvider>
</QueryProvider>;다만 LazyMotion을 쓰려면 기존에 motion.div로 쓰던 부분을 전부 m.div로 바꿔야 한다. motion은 전체 기능을 포함한 컴포넌트고 m은 LazyMotion이 제공하는 feature set에 의존하는 경량 컴포넌트다. 프로젝트 전체에서 motion을 m으로 교체하는 작업이 같이 필요했는데 규모가 크지는 않아서 금방 끝났다.
react-day-picker 다이나믹 임포트
react-day-picker는 달력 컴포넌트 하나에만 쓰이는데 번들에는 라이브러리 전체가 포함돼 있었다. 모든 페이지에서 달력을 쓰는 것도 아닌데 초기 번들에 같이 들어가는 건 낭비였다.
React.lazy로 다이나믹 임포트를 적용했다. 이렇게 하면 달력 컴포넌트가 실제로 렌더링될 때만 react-day-picker를 불러온다.
const DayPickerLazy = React.lazy(() =>
import('react-day-picker').then((m) => ({ default: m.DayPicker })),
);React.lazy는 컴포넌트를 처음 렌더링하는 시점에 import()를 실행해서 해당 모듈을 비동기로 불러온다. 초기 번들에는 포함되지 않고 별도 청크로 분리되기 때문에 첫 페이지 로드 시 다운로드해야 하는 JS 크기가 줄어든다. Suspense로 감싸서 로딩 중에는 fallback UI를 보여주게 했다.
Next.js 빌드 최적화 설정
next.config.ts에서 몇 가지 실험적 옵션도 켰다.
experimental: {
optimizeCss: true,
optimizePackageImports: ['framer-motion', '@tanstack/react-query'],
esmExternals: true,
},
compiler: {
removeConsole: process.env.NODE_ENV === 'production',
},optimizePackageImports 는 barrel file 문제를 해결해준다. barrel file이란 index.ts에서 모든 모듈을 re-export하는 패턴인데 import { motion } from 'framer-motion'처럼 쓰면 번들러가 framer-motion의 index.ts를 따라가서 전체 모듈을 분석하게 된다. optimizePackageImports를 설정하면 Next.js가 이걸 직접 경로 임포트로 변환해서 tree-shaking이 더 효과적으로 동작하게 만들어준다. 앞서 LazyMotion으로 framer-motion의 feature set을 줄였는데 이 설정까지 같이 적용하니까 bundle-analyzer 트리맵에서 framer-motion이 차지하는 영역이 눈에 띄게 줄어든 걸 확인할 수 있었다.
optimizeCss 는 내부적으로 critters라는 도구를 사용한다. 빌드 시점에 각 페이지의 HTML을 분석해서 최초 렌더링에 필요한 CSS만 <style> 태그로 인라인 삽입하고 나머지 CSS는 비동기로 로드한다. 외부 CSS 파일을 다운로드할 때까지 렌더링이 블로킹되는 시간을 줄여주는 역할이다. Lighthouse의 Render-blocking resources 항목에서 CSS 관련 경고가 사라진 걸 확인할 수 있었다.
removeConsole 은 프로덕션 빌드에서 console.log, console.warn 등 모든 console.* 호출을 제거한다. 성능에 큰 영향을 주는 설정은 아니지만 프로덕션에서 불필요한 콘솔 출력을 방지하고 번들 크기도 미세하게 줄여준다.
이미지 최적화 설정
images: {
minimumCacheTTL: 31536000,
formats: ['image/avif', 'image/webp'],
deviceSizes: [360, 640, 828, 1080, 1200, 1920],
},formats 에 avif를 webp보다 앞에 두면 브라우저가 avif를 지원하는 경우 avif를 우선 사용한다. avif는 webp보다 압축률이 높아서 같은 화질에서 파일 크기가 더 작다. 모임 카드 썸네일 기준으로 원본 대비 이미지 크기가 상당히 줄어든 걸 Network 탭에서 확인할 수 있었다.
minimumCacheTTL 을 31536000(1년)으로 설정했다. Next.js Image Optimization API가 생성한 최적화 이미지를 1년간 캐시하는 설정이다. 한 번 방문한 페이지를 다시 열면 이미지 요청 자체가 발생하지 않아서 재방문 시 체감 속도가 확실히 빨라졌다.
deviceSizes 를 커스텀한 이유는 기본값에 모바일 해상도가 부족했기 때문이다. 360px을 추가해서 저해상도 모바일 기기에서 불필요하게 큰 이미지를 받지 않도록 했다.
추가로 sharp 도 설치했다. Next.js Image Optimization은 이미지를 avif/webp로 변환할 때 내부적으로 이미지 처리 엔진을 쓰는데 sharp가 없으면 기본 엔진을 사용하게 된다. sharp는 C 기반 라이브러리라 변환 속도가 훨씬 빠르고 Next.js 공식 문서에서도 프로덕션 환경에서는 sharp 설치를 권장하고 있다.
개선 결과
최적화 작업 후 Lighthouse를 다시 돌려봤다.
- Lighthouse Performance: 78 → 99
- LCP: 4s → 0.9s
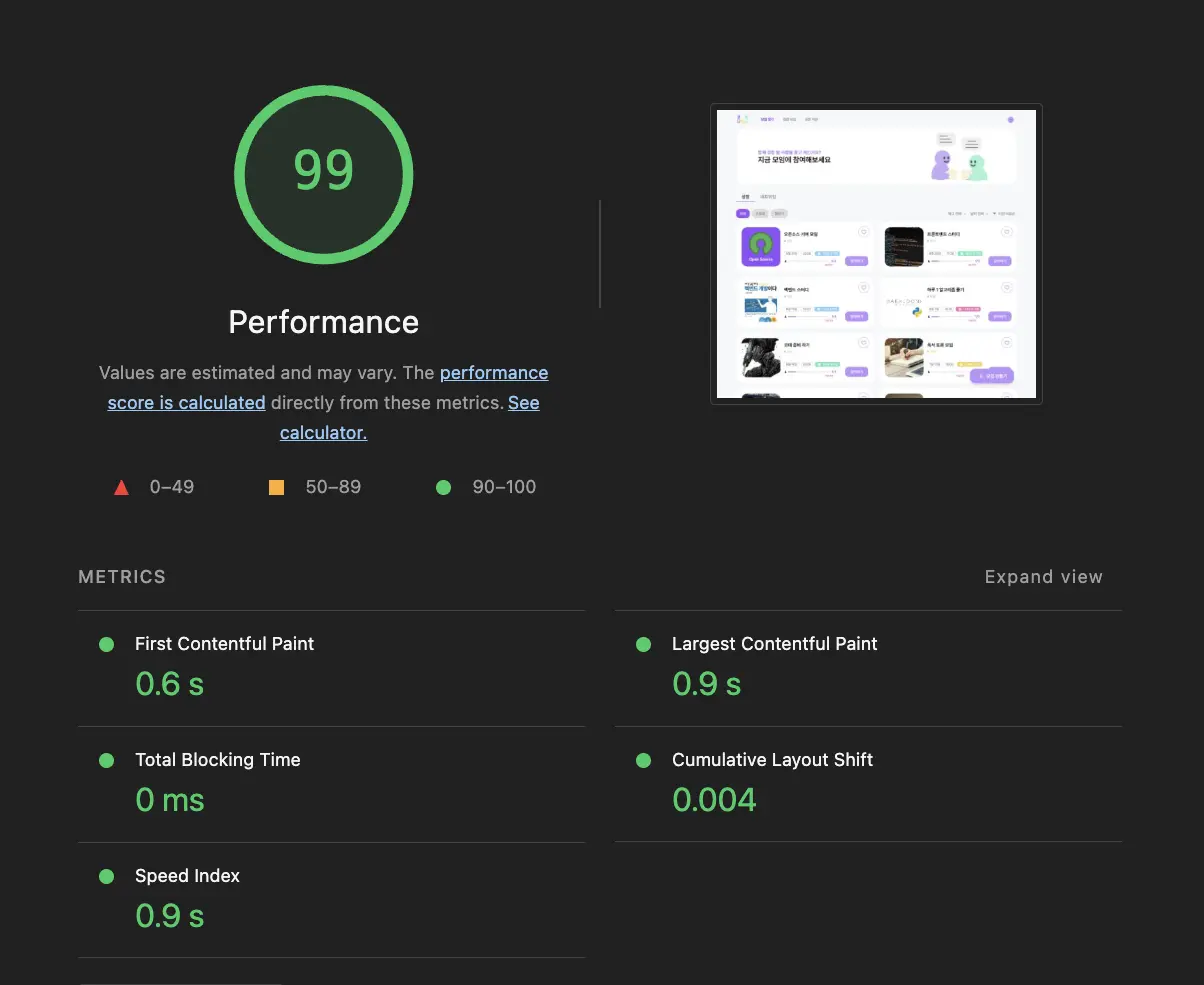
세 가지 작업 중 SSR prefetch가 LCP에 가장 직접적인 영향을 줬다. 서버에서 데이터를 채워서 보내니까 클라이언트에서 API를 기다리는 단계 자체가 사라졌고 체감상 이것만으로 LCP가 가장 크게 줄었다.
폰트 최적화는 다운로드 크기를 ~3.9MB에서 수십 KB로 줄여서 전체 페이지 로드 시간을 단축해줬다. 번들 최적화는 JS 파싱 및 실행 시간을 줄여서 TBT(Total Blocking Time)와 TTI(Time to Interactive) 개선에 기여한 것 같다. 각각의 효과가 극적이라기보다는 여러 개가 누적돼서 전체 점수를 끌어올린 느낌이었다.
마치며
성능 최적화는 생각보다 손대야 할 곳이 많았다. 데이터 페칭 타이밍, 폰트 로딩 방식, 번들 구성, 이미지 포맷까지 하나만 고쳐서 해결되는 게 아니라 여러 영역을 같이 건드려야 했다. 결국 정답이 하나로 정해져 있는 게 아니라 서비스 상황에 맞게 판단하는 과정이라는 걸 배웠다.